I have always imagined that paradise will be a kind of library.
--- Jorge Luis Borges
Sighted on AbeBooks---a favorite site. info on source
I have always imagined that paradise will be a kind of library.


Many years later Newton told at least four people that he had been inspired by an apple in his Woolsthorpe garden--perhaps an apple actually falling from a tree, perhaps not. He never wrote of an apple. He recalled only:I began to think of gravity extending to the orb of the Moon . . .
---gravity as a force, then, with an extended field of influence; no cutoff or boundary---& computed the force requisite to kep the Moon in her Orb with the force of gravity at the surface of the earth . . . & found them answer pretty nearly. All this was in the two plague years of 1665-1666. For in those days I was in the prime of my age for invention & minded mathematicks and Philosophy more than at any time since.
The apple was nothing in itself. It was half of a couple---the moon's impish twin. As an apple falls toward the earth, so does the moon; falling away from a straight line, falling around the earth.


BX/CX = x. Using the standard formula for area of a triangle, and recognizing that the heights are equal in each case, we can show that the areas (designated as |ABC|) of the triangles below are in the same ratio:

y = CY / AY and z = AZ / BZ, then:
Counter class from here.




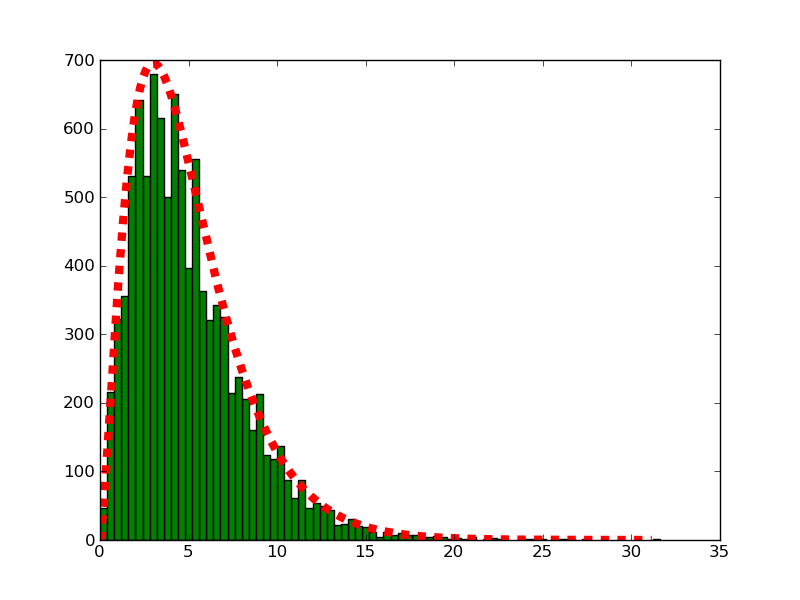
cluster function finds the two points that are the closest together, and averages them together, using the weights."In one of the first studies of the Poisson distribution, von Bortkiewicz considered the frequency of deaths from kicks in the Prussian army corps. From the study of 14 corps over a 20-year period, he obtained the data shown in [the] Table. Fit a Poisson distribution to this data and see if you think that the Poisson distribution is appropriate."